2025年批次
基于自注意力机制和多模型融合的流域水质变化趋势预测研究
学生申报
创新训练项目
工学
计算机类
学生来源于教师科研项目选题
一年期
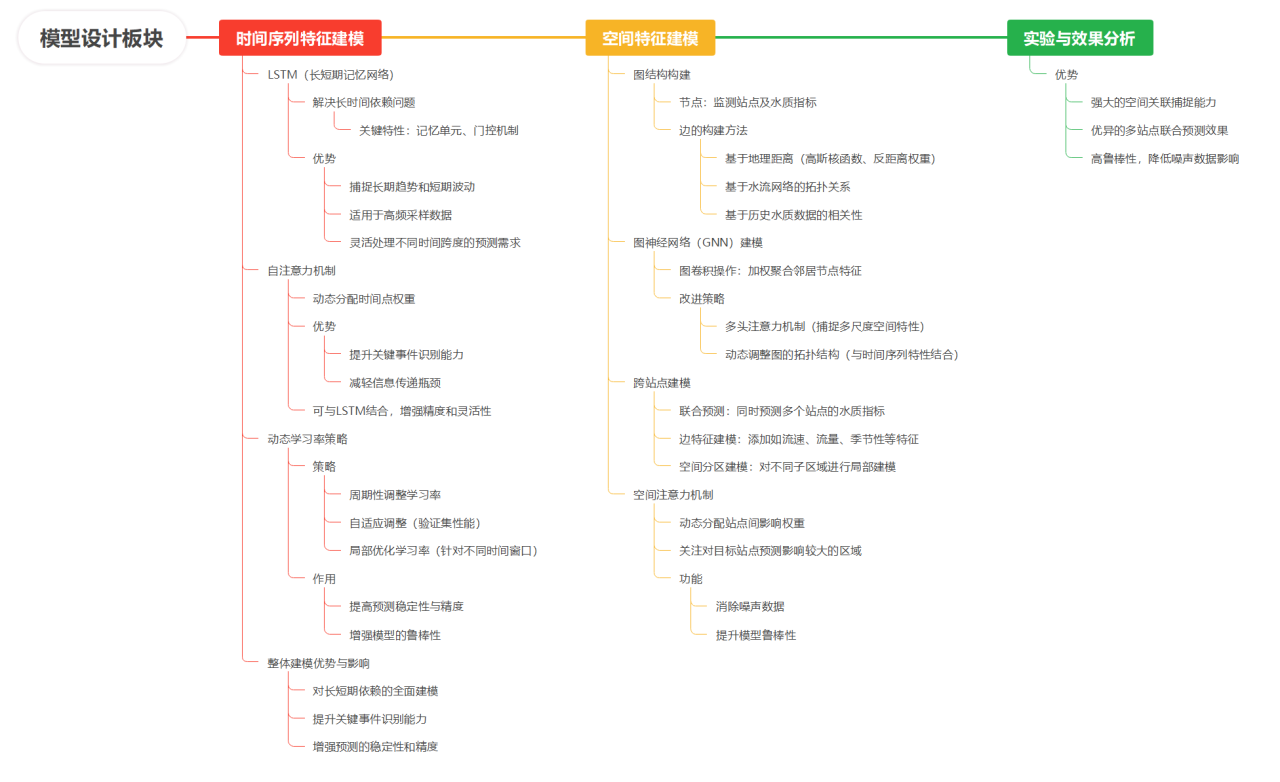
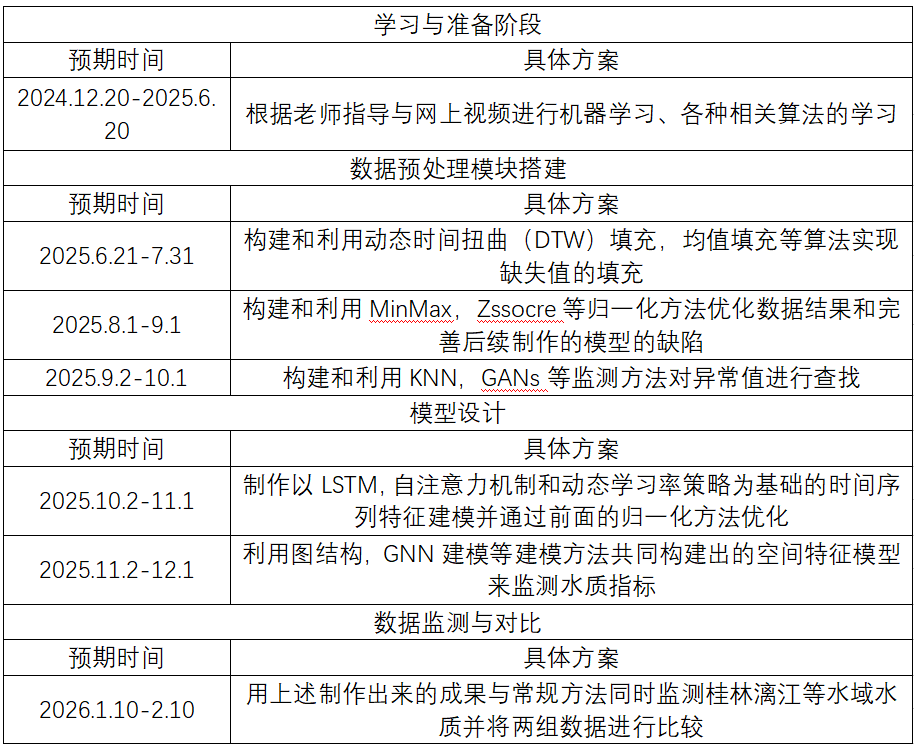
本研究旨在构建一个高效可靠的水质监测数据建模框架,以应对数据的时间动态和空间分布复杂性,并解决数据缺失和异常值问题。研究目标包括开发多策略数据预处理方法、构建融合LSTM和GNN的混合模型以挖掘数据时空特性,并通过实验验证模型的有效性,为水资源保护和环境管理提供技术支持。
无
无
本研究旨在构建一个高效可靠的水质监测数据建模框架,以应对数据的时间动态和空间分布复杂性,并解决数据缺失和异常值问题。研究目标包括开发多策略数据预处理方法、构建融合LSTM和GNN的混合模型以挖掘数据时空特性,并通过实验验证模型的有效性,为水资源保护和环境管理提供技术支持。
校级